Benchmark Report: Nemotron-3-Nano vs Devstral-Small-2¶
Date: 2026-02-07 Hardware: RTX 4090 (24 GB VRAM) Runtime: llama.cpp router mode, single GPU Temperature: 0.2 (fixed for all models) Evaluator: Claude Opus 4.6
Executive Summary¶
Devstral-Small-2-24B (Q4_K_M) outperforms Nemotron-3-Nano-30B-A3B (UD-Q4_K_XL) across nearly all quality and latency metrics. Nemotron's only advantage is raw generation speed (89 tok/s vs 59 tok/s), but this is negated by its 30x higher time-to-first-token and frequent response truncation due to hidden reasoning tokens.
Recommendation: Use Devstral-Small-2 as the primary code model. Nemotron is not suitable for interactive use at the current 512 max_tokens limit because its reasoning tokens consume the output budget invisibly.
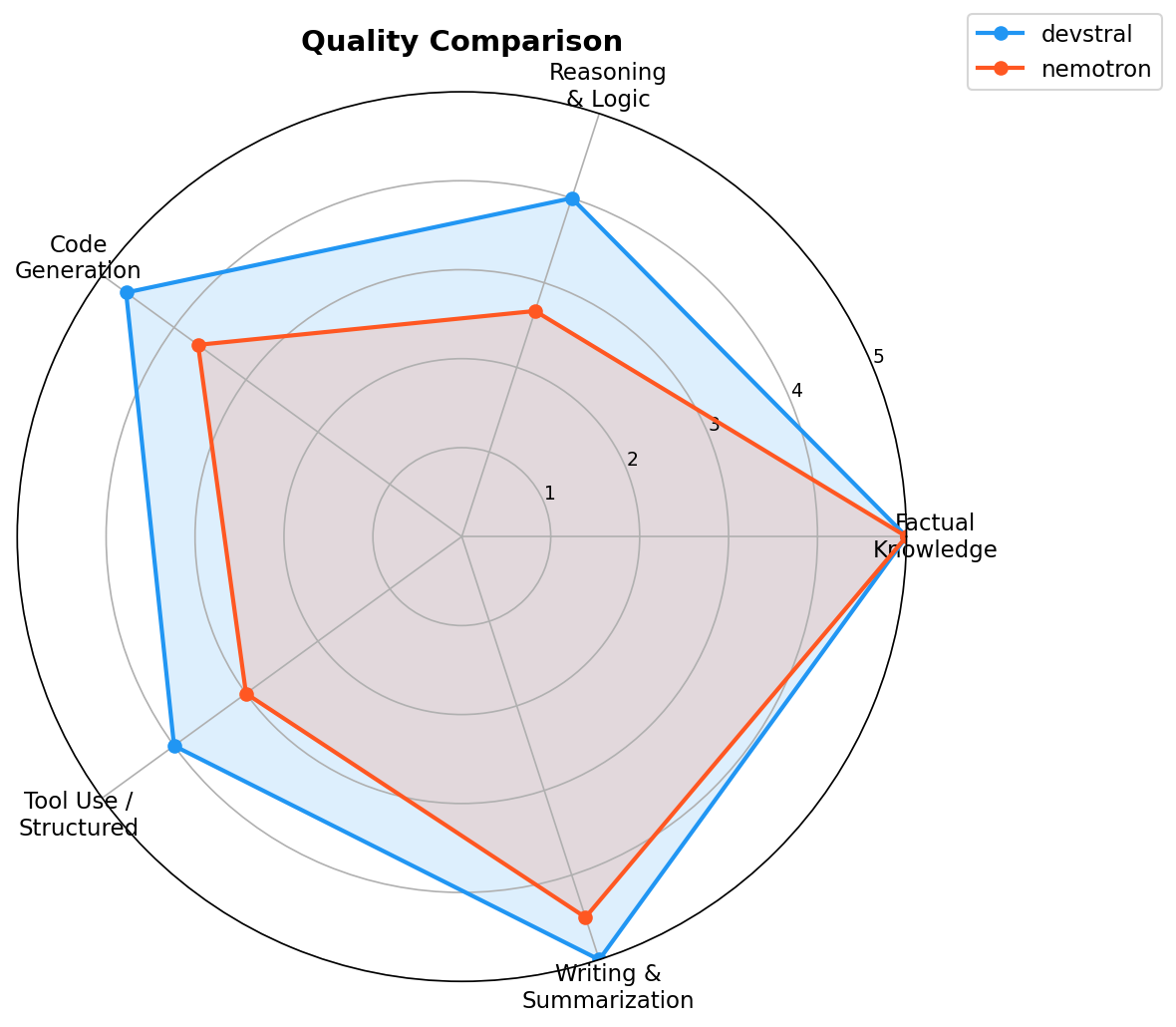
Quality Scores (1-5)¶
| Category | Devstral | Nemotron | Winner |
|---|---|---|---|
| Factual Knowledge | 5.0 | 5.0 | Tie |
| Reasoning & Logic | 4.0 | 2.7 | Devstral |
| Code Generation | 4.7 | 3.7 | Devstral |
| Tool Use / Structured Output | 4.0 | 3.0 | Devstral |
| Writing & Summarization | 5.0 | 4.5 | Devstral |
| Overall Average | 4.5 | 3.8 | Devstral |
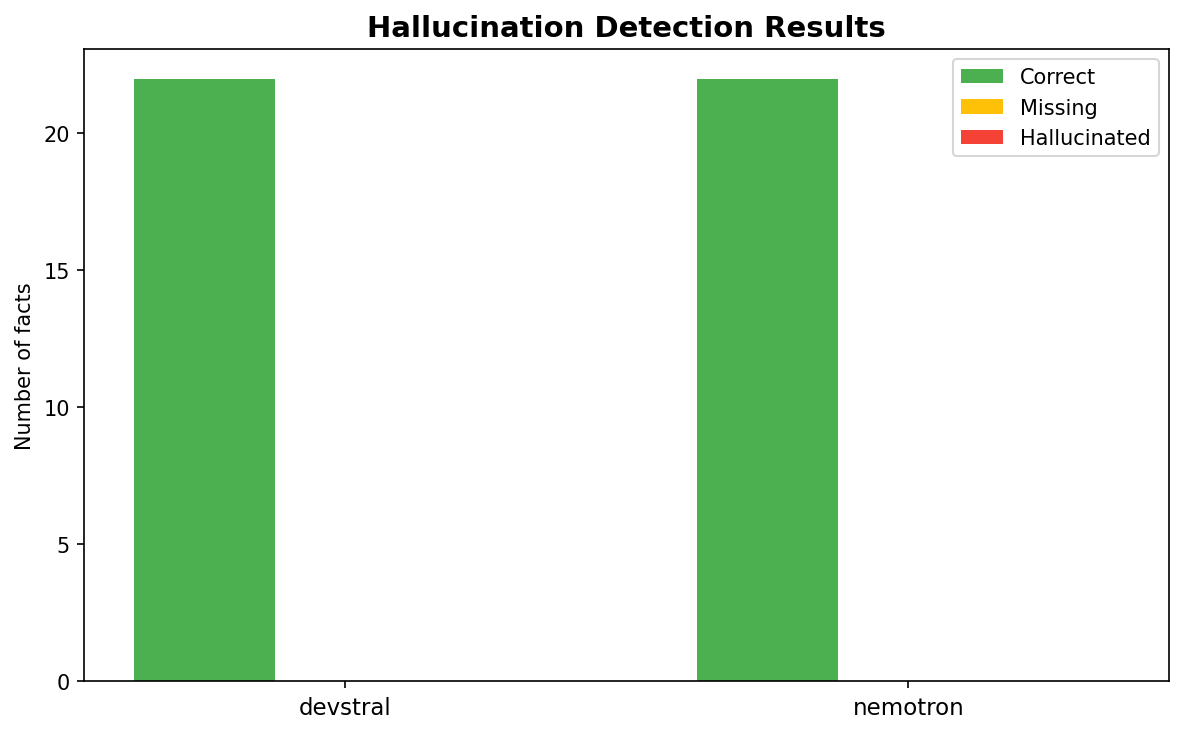
Hallucination Detection¶
Both models achieved 0% hallucination rate across all factual prompts (22 facts checked per model). No forbidden claims detected, no fabricated laws, no Pluto-as-planet errors. Both models are factually reliable at temperature 0.2.
| Metric | Devstral | Nemotron |
|---|---|---|
| Facts checked | 22 | 22 |
| Facts correct | 22 | 22 |
| Facts hallucinated | 0 | 0 |
| Hallucination rate | 0.0% | 0.0% |
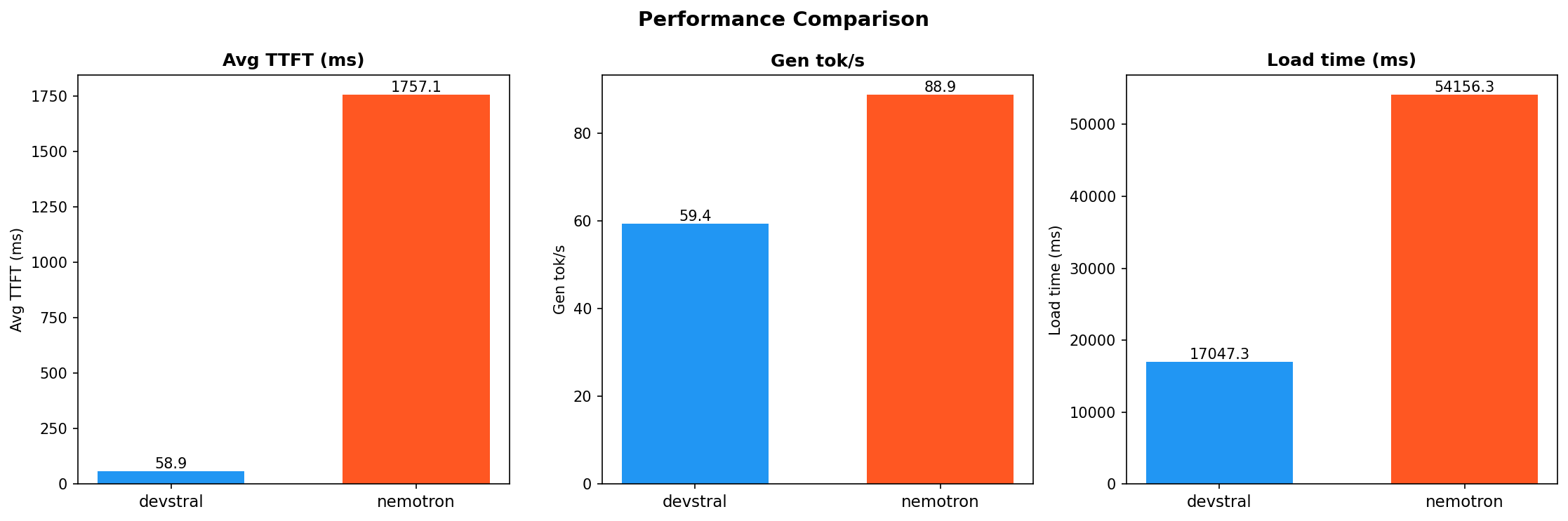
Performance Metrics¶
| Metric | Devstral | Nemotron | Notes |
|---|---|---|---|
| Avg TTFT | 59 ms | 1,757 ms | Devstral 30x faster |
| Min/Max TTFT | 37-108 ms | 0-4,893 ms | Nemotron TTFT is highly variable |
| Gen tok/s | 59.4 | 88.9 | Nemotron 50% faster generation |
| Prompt tok/s | 1,626-2,740 | 250-314 | Devstral 6-10x faster prompt processing |
| VRAM (loaded) | 21,715 MB | 22,641 MB | Both fit on 24 GB with ~2 GB headroom |
| Model load time | 17.0 s | 54.2 s | Devstral 3x faster to load |
| Model unload time | 3-4 ms | 3 ms | Instant for both |
| VRAM after unload | 2,575 MB | 2,575 MB | Same baseline |
TTFT Analysis¶
Nemotron's high TTFT is caused by its reasoning/thinking phase. Even at temperature 0.2, the model generates internal reasoning tokens before producing visible output. These tokens consume the max_tokens budget but are not visible in the response. This manifests as:
- Long pauses before any output appears (up to 5 seconds)
- Truncated responses when reasoning consumes most of the token budget
- Empty responses when ALL tokens are consumed by reasoning (constraint puzzle)
Devstral has no reasoning phase, delivering its first token in 37-108ms consistently.
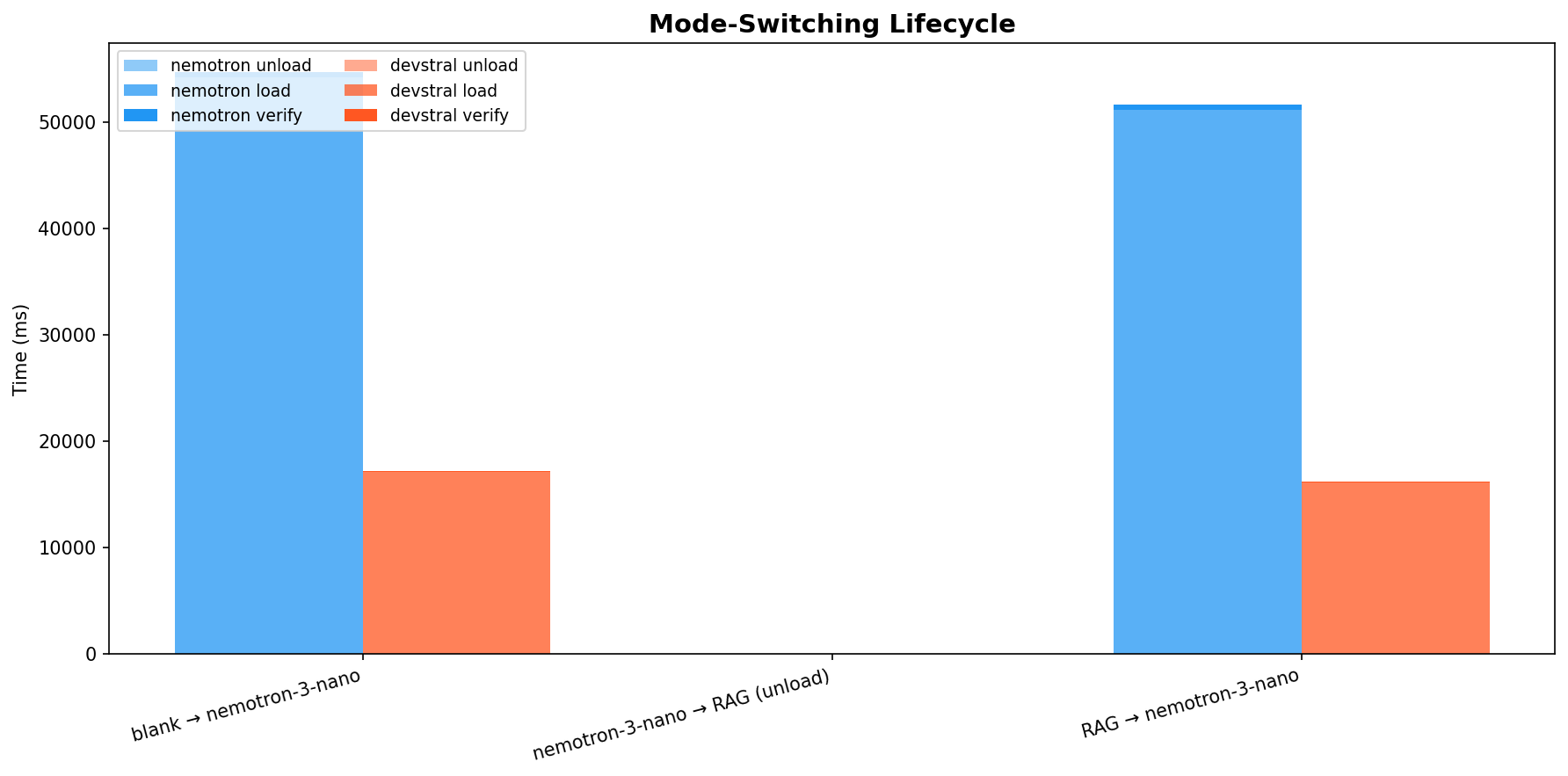
Mode-Switching Lifecycle¶
Transition times for blank -> code_model -> RAG -> code_model:
| Transition | Devstral | Nemotron |
|---|---|---|
| blank -> model (load) | 17,047 ms | 54,156 ms |
| blank -> model (verify TTFT) | 83 ms | <1 ms* |
| model -> RAG (unload) | 4 ms | 3 ms |
| VRAM freed after unload | 19,140 MB | 20,064 MB |
| RAG -> model (reload) | 16,056 ms | 51,138 ms |
| RAG -> model (verify TTFT) | 82 ms | <1 ms* |
| Total round-trip | 33,272 ms | 105,300 ms |
*Nemotron's verify TTFT shows 0ms because the short "READY" response completes without a visible thinking phase. Real TTFT for substantive prompts averages 1,757ms.
User-visible switch time: - Devstral: ~17s to switch modes (acceptable for IDE workflow) - Nemotron: ~54s to switch modes (noticeable delay)
Detailed Scoring Rationale¶
Factual Knowledge (Devstral 5.0 / Nemotron 5.0)¶
Both models answered all three factual prompts perfectly: - Thermodynamics: All four laws correct with core principles - Solar System: All 8 planets in order, Jupiter largest, Mercury smallest - Programming Languages: Correct years and creators for Python/Java/Rust
Nemotron provided slightly more detailed responses (extra context about organizations), but both achieved perfect accuracy.
Reasoning & Logic (Devstral 4.0 / Nemotron 2.7)¶
- Syllogism: Both correct (cannot conclude). Nemotron used formal logic notation which was more rigorous.
- Math problem: Devstral solved correctly (10:37 AM). Nemotron's response was truncated at 512 tokens with no answer reached -- thinking consumed most tokens.
- Constraint puzzle: Devstral gave a wrong answer (yellow adjacent to green, violating constraint). Nemotron returned an empty response (all 512 tokens consumed by thinking, 0 visible output).
Code Generation (Devstral 4.7 / Nemotron 3.7)¶
- FizzBuzz: Both correct. Devstral slightly cleaner. Nemotron's docstring had a minor example bug.
- Binary Search: Devstral complete with a sorted-check caveat (O(n log n)). Nemotron's code was truncated mid-docstring.
- Bug Detection: Both correctly identified the merge_sorted bug. Devstral provided a complete fix with demonstration. Nemotron's was correct but truncated.
Tool Use (Devstral 4.0 / Nemotron 3.0)¶
- JSON Extraction: Both correct. Nemotron returned plain JSON (as asked). Devstral wrapped it in markdown fences (minor format issue).
- Function Calling: Devstral returned correct JSON. Nemotron returned
only
{-- thinking consumed all tokens, producing no useful output.
Writing (Devstral 5.0 / Nemotron 4.5)¶
- Summarization: Both produced exactly 3 bullet points, accurate and comprehensive. Tie.
- Technical Explanation: Both used good analogies. Devstral stayed under 150 words. Nemotron exceeded the limit (~167 words).
Key Findings¶
1. Nemotron's Reasoning Tokens Are a Double-Edged Sword¶
The model's internal reasoning capability (even with enable_thinking=false
in the template) still produces hidden tokens that consume the output budget.
At 512 max_tokens, this causes:
- 3 of 13 responses truncated or empty
- Unpredictable response length
- User-perceived quality drop
Mitigation: Increase max_tokens to 2048+ for Nemotron, or use the model only for tasks where reasoning overhead adds value (math, complex analysis) and shorter outputs are acceptable.
2. Devstral Is the Better All-Rounder¶
Devstral delivers consistent, predictable output across all categories with excellent latency. It is the better choice for: - Interactive coding (low TTFT, consistent output) - Tool calling and structured output - IDE integration (faster mode switching)
3. Both Models Are Factually Reliable¶
Zero hallucinations detected across 22 fact checks per model at temperature 0.2. Both can be trusted for factual queries at low temperature.
4. VRAM Usage Is Comparable¶
Both models fit comfortably on the 24 GB RTX 4090 with ~2 GB headroom for the embedding model: - Devstral: 21.7 GB loaded - Nemotron: 22.6 GB loaded - Baseline after unload: 2.6 GB
Charts¶
Quality Comparison (Radar)¶
Performance Comparison¶
Hallucination Detection Results¶
Mode-Switching Lifecycle¶
Methodology¶
See ../README.md for full methodology, including prompt suite, hallucination detection approach, and scoring rubric.